
Xinqiao Zhang
Senior Machine Learning Scientist at CoreLogic
Specializing in GenAI, Deep Learning, and Trustworthy ML
LinkedIn | Resume | GitHub | Schedule a Meeting
Project: Optimization and Acceleration of Deep Learning on Various Hardware Platforms. View Project report
In this project, I use python to optimuze deep neural network operations, libraries and implementation steps related to accelerating the performance of deep neural networks.
1. Purning
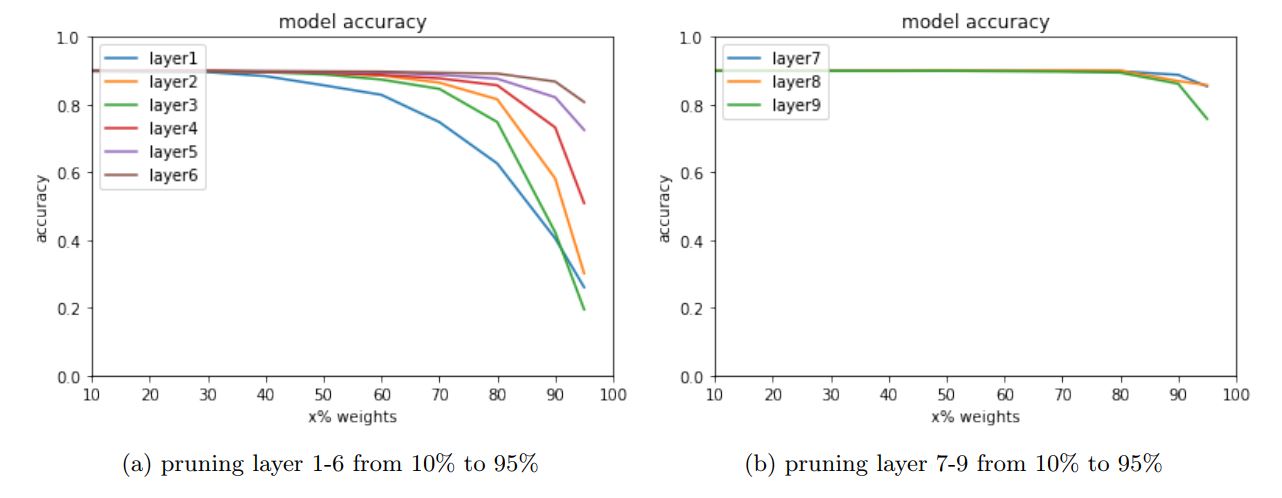 Pruning is a technique in machine learning and search algorithms that reduces the size of decision trees by removing sections of the tree that provide little power to classify instances. Pruning reduces the complexity of the final classifier, and hence improves predictive accuracy by the reduction of overfitting [4]. Especially for
hardware implementation, pruning can take advantage of limited hardware IOT devices or other low-power devices. By applying pruning, it can both improve the speed and save power consumption, which is a really hot topic recently.
Pruning is a technique in machine learning and search algorithms that reduces the size of decision trees by removing sections of the tree that provide little power to classify instances. Pruning reduces the complexity of the final classifier, and hence improves predictive accuracy by the reduction of overfitting [4]. Especially for
hardware implementation, pruning can take advantage of limited hardware IOT devices or other low-power devices. By applying pruning, it can both improve the speed and save power consumption, which is a really hot topic recently.
2. Tucker decomposition
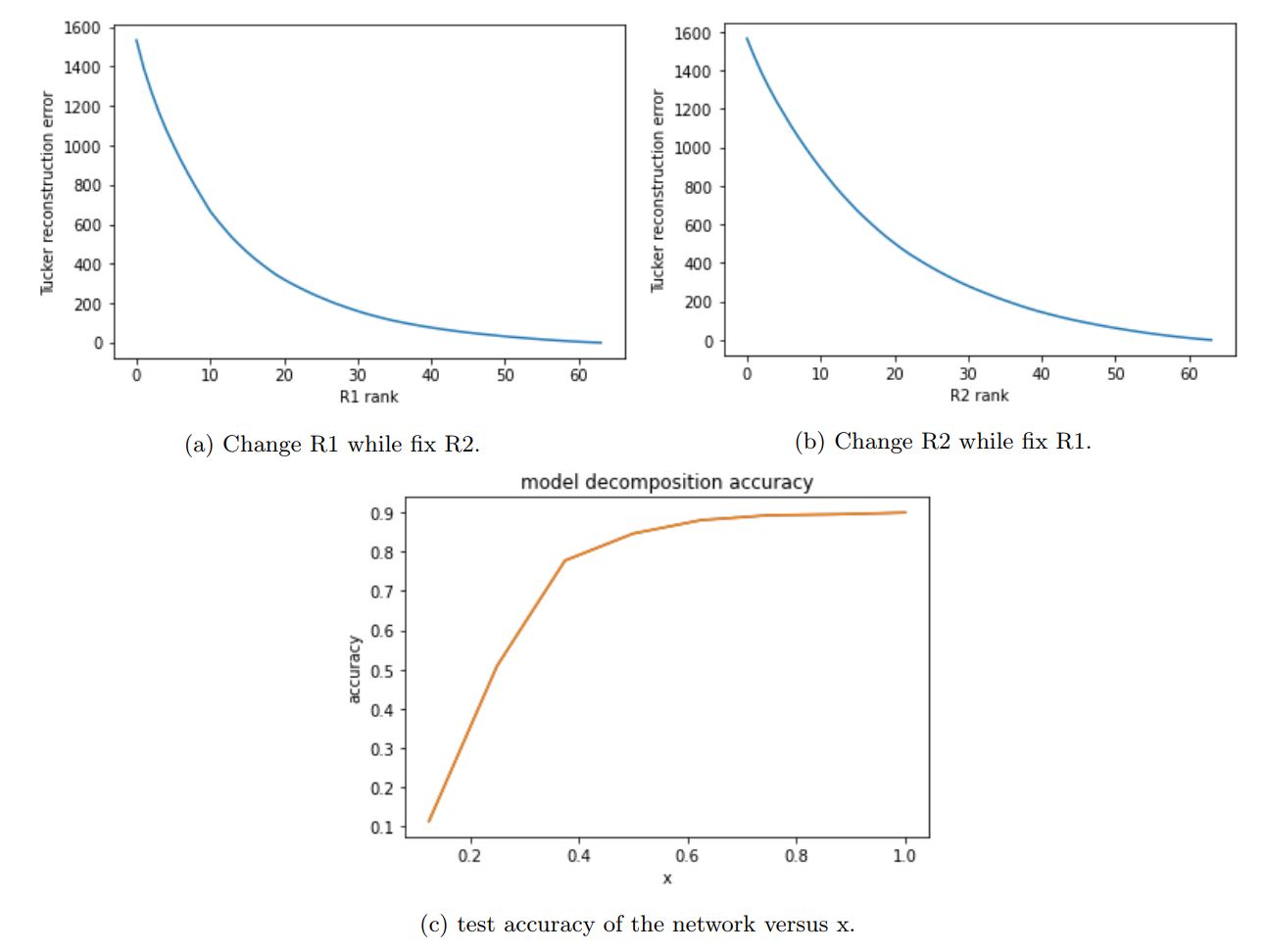 Tucker decomposition is a method that decomposes a tensor into a smaller core tensor and a set of matrices. Tucker decomposition is a higher order extension of the singular value decomposition (SVD) of matrix, in the perspective of computing the orthonormal spaces associated with the different modes of a tensor. It simultaneously analyzes mode-n matricizations of the original tensor, and merges them with the core tensor.
Tucker decomposition is a method that decomposes a tensor into a smaller core tensor and a set of matrices. Tucker decomposition is a higher order extension of the singular value decomposition (SVD) of matrix, in the perspective of computing the orthonormal spaces associated with the different modes of a tensor. It simultaneously analyzes mode-n matricizations of the original tensor, and merges them with the core tensor.
3. Conclusion:
Therefore, the main idea of this project is to learn some methods to optimize and accelerate the deep neural networks and make them compatible with the current various hardware platforms. I think the idea of optimization and acceleration is with the development of all kinds of IOT devices, some reliable and low-power hardware platforms are needed as well. And this is a very hot topic and very promising in the future.